PII scrubbing, provenance tracking, DMCA process, and what happens to your data when you cancel — the full story, in plain language.
PostGrad sits between source material and an agent's API call. That means the same data flows through several stages — upload, extraction, storage, serving — and at each stage we do specific things to protect both the licensor who published it and the subscriber who consumes it. This walkthrough covers the whole chain in plain language.
Before you start: nothing — this is reference material, not a task.
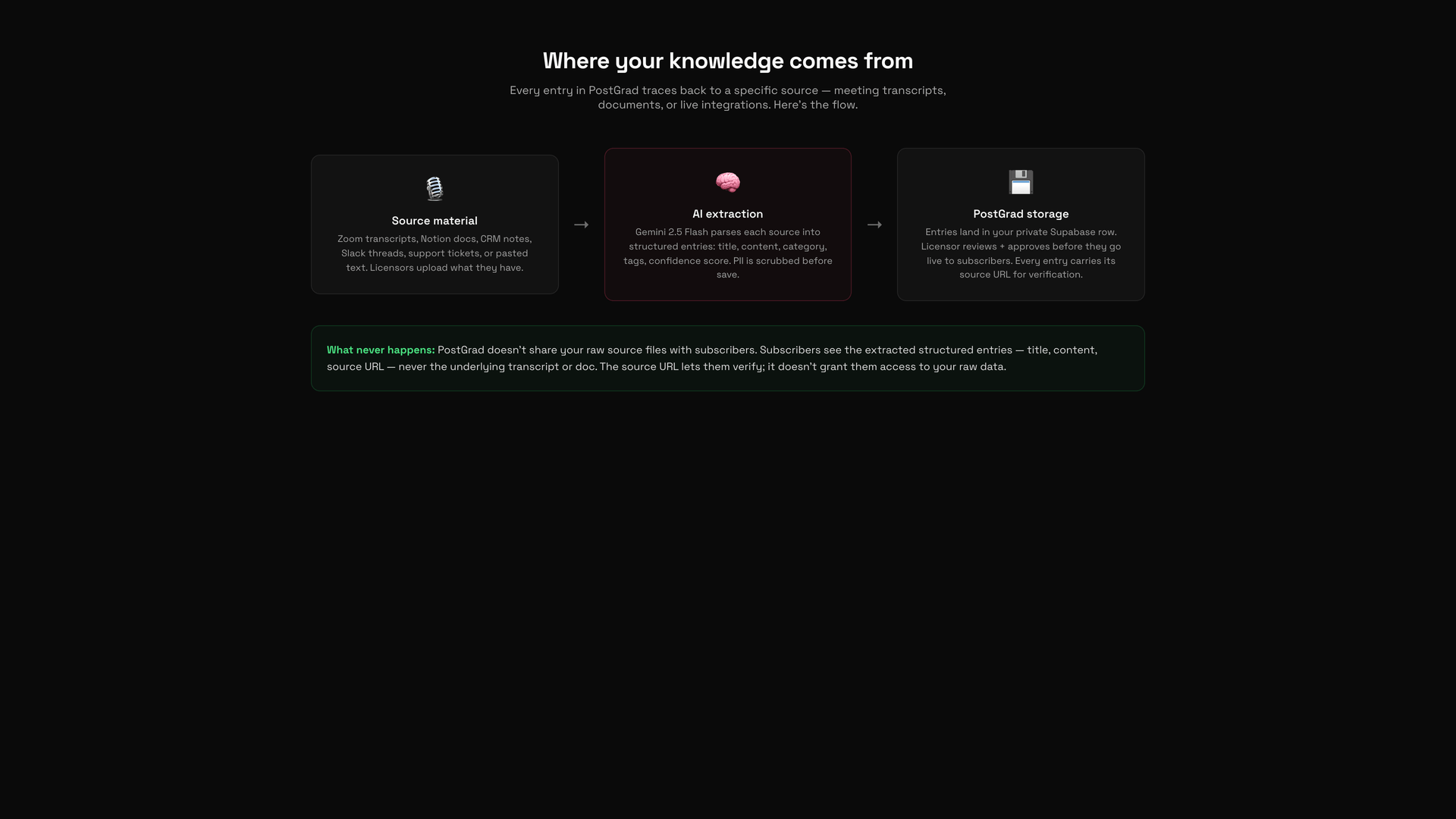
1Source material: where it comes from
A diagram showing the three sources of feed entries: licensor uploads, PostGrad curated feeds, and connected third-party sources.
What's never a source: scraped third-party sites, user accounts from other platforms, or anything the licensor doesn't have rights to. The publisher agreement explicitly requires licensors to own or have a license for everything they upload.
2PII scrubbing: what gets removed
An example of a paragraph of text with PII highlighted — an email, a phone number, and an API key — showing the redacted version alongside.
3Provenance: every entry carries its source
An entry detail view showing source metadata — source URL, extraction timestamp, confidence score, and licensor ID.
4DMCA and takedowns
The DMCA takedown request form showing fields for the claimant, the infringing URL, and the basis for the claim.
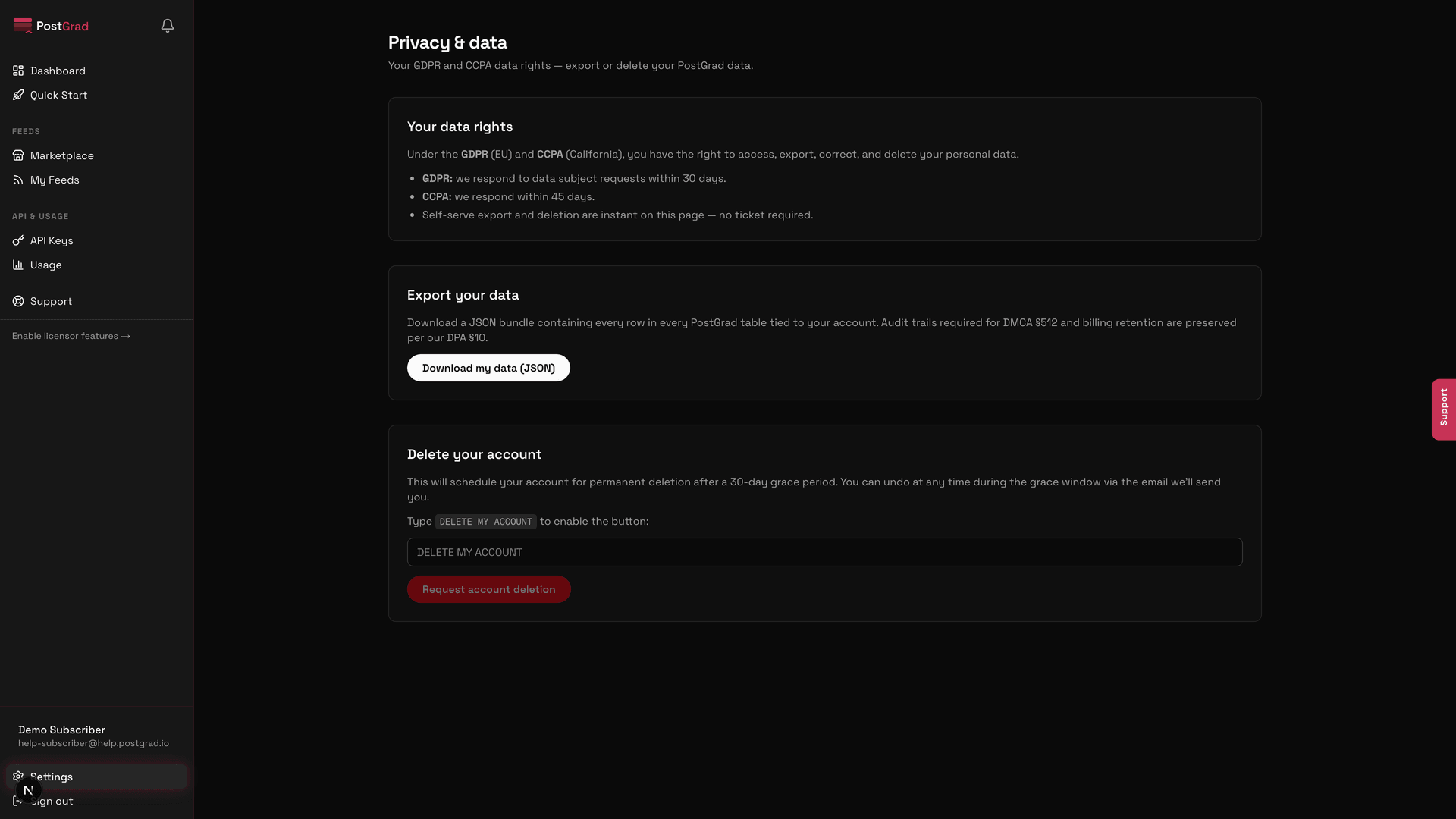
5What happens when a subscriber cancels
A timeline showing subscriber-cancel consequences: API access ends, usage history retained, no new events recorded.
6What happens when a licensor unpublishes
A timeline showing licensor-unpublish consequences: entries stop serving, subscribers get notified, prorated refund issued.
7Security and compliance posture
A summary of PostGrad's security posture: encryption at rest, TLS in transit, RLS on every table, rotated vendor secrets, audit logs.